the ridiculousness of academia – where my time is simultaneously worth $100+/hr as a contractor, $40/hr as a teaching assistant, and $0/hr as a PhD student (and without health insurance to boot).
There’s no way this is worth it salary-wise. Consider that I’d have to earn $200k for the next 5 years in order to average $100k for 10 years. (how long will the tech bubble last anyway?)
Other things to balance: staying in one place. I’ve never been good at that. The pandemic is helping oddly enough. Most years I move at least once a year…
In the US, looks like vaccine rollout building up steam. Hear reports about vaccines being available for everyone by the end of May. (In the backdrop of reports of rich countries hoarding vaccines)
Dispatches from UN Wire
Pandemic unlikely to end in 2021, WHO official says Global coronavirus case numbers increased last week after six consecutive weeks of decline as infections climbed in the Americas, Europe, Southeast Asia and the eastern Mediterranean, the World Health Organization reports. WHO Director-General Dr. Tedros Adhanom Ghebreyesus says that countries should not rely solely on vaccinations to control the spread of the virus,
Politics
Still?!
Yes, trying to get parents to spend more time on local issues we can actually affect. Fair Fight action:
The bill now heads to the state Senate, where a committee voted Monday to end no-excuse absentee voting, which would require most voters to cast ballots in person. That legislation could receive a vote in the full Senate within days.
Space
Mars looks pretty! The landing was so spectacular – I’m still so proud of the achievements of scientists and engineers the world over!!
Getting a building size object to belly flop was great.
Computer Travails
Had quite the scare the other day, where suddenly all USB-C ports on my laptop stopped working, which in this case meant my laptop stopped charging. Pretty anxiety-inducing to just watch the battery go down and not be able to charge it.
Apparently Lenovo had some issue where laptops would stop charging through usb-c port! I feel a little vindicated about my horrible issues with my old laptop. Which caused me to get new one under all the warranties (I’m sure for naught), and also as new (under Lenovo sale – the specs are awful, 128 GB hd / 8 GB ram, and I’ve just been tacking on components over time. Not sure how cost-effective it has been in the end, definitely not time-effective). I updated the firmware (surprisingly easy, download the .iso file from lenovo, extract into a .img, burn with e.g. etcher.io onto a USB, then boot from that USB).
I did investigate whether I can update through the new fwupdmgr but alas it was not to be. Otherwise the commands would have been:
sudo fwupdmgr get-devices
for d in system-manufacturer system-product-name bios-release-date bios-version
do
echo "${d^} : " $(sudo dmidecode -s $d)
done
sudo fwupdmgr refresh --force
sudo fwupdmgr update
For my curiosity, X1 Yoga v2 before:
├─System Firmware: │ Device ID: 123fd4143619569d8ddb6ea47d1d3911eb5ef07a │ Current version: G5ET93WW (2.53 ) │ Vendor: LENOVO │ Update Error: UEFI Capsule updates not available or enabled │ GUID: 230c8b18-8d9b-53ec-838b-6cfc0383493a ← main-system-firmware │ Device Flags: • Internal device │ • Requires AC power │ • Needs a reboot after installation
Trustworthy W530… firmware from 2013 still going strong.
Canonical Naming
This is definitely coming up as I start applying to things… I kind of lost my chance to standardize my name after the beginning of Harvard. I wonder why I didn’t go with Rui. I s’pose my email address was chosen already. Maybe I just felt that Rui was too hard to pronounce. Now I have a pretty bad situation where I have a PI at MIT who knows me by one name… a PI at another school who knows me by another… and my website lists a third, since I don’t want certain people to be aware of this whole situation… I can’t say the confusion is likely to help me. I could trash one of the names now that I’m barely affiliated with Harvard it feels like. But it feels utterly wrong to go by Nancy there.
Hearing my parents speak about (trans)gender issues, I guess I always charitably thought my travails had nothing to do with my really strange choices around how to present myself. But maybe people in cities are probably pretty open-minded since they have to deal with so many strangers all the time, vs in the suburbs I just deal with the same few people all the time. eh.
Definitely still in denial, but tbh going by a totally new name makes it kinda hard. Oh well! Maybe I’m doomed to making small money in random jobs and a life of instability. Like, trying to keep perspective, but not sure which direction y’know?
Perspective
On the one hand, well, I managed to reach basically 30 without dying, which I didn’t expect. Hearing about someone I lived on a hall with in undergrad had gotten a nice career in NY, married, bought a house, move to the burbs, had a kid, and then committed suicide early on in the pandemic. Who had issues with depression I never knew about.
Life is unfair. So, practice being grateful every day.
‘specially the subject matter I’m working on. Now that I’m on health insurance, I should certainly see a therapist regularly. I don’t even know that I really believe it’ll help. I in fact think it will be really mentally exhausting. But it’s on the to-do list, y’know?
Choices
I made my choices this year feeling like I would not want to grow old and feel like I didn’t put the time in to do the right thing, with regards to the pandemic and the elections. But here I am on the other side and it still keeps going. Republicans are making it harder to vote, now that they’ve gotten it into their minds that fewer voters is better (which, what the hell? win on platform not attacking one of the pillars of democracy). Although in context I guess technically our country was founded like this from the beginning. And of course, on the other activist side, the pandemic just keeps going.
So was it worth it? I went to these fancy schools, but was it worth it? Would I be happier now if I just had boatload of money? Some days it sure feels like it. My friends my age are buying houses, I’m living with my parents, unemployed, constantly worrying about health insurance.
(I guess I have been rejected out of hand for an internship, so feeling a little low today. I know it should be rather an indicator that I’m applying to things at the right level. But it still hurts!)
Actually come to think of it, I’ve yet to receive a paper rejection, hah! Guess I’m not submitting enough papers. (Underlying it still, the feeling of not being a real Computer Scientist, despite now having my master’s degree in it. Since I haven’t done True Computer Science research according to my quals committee).
Grad students
Well I started writing this and accidentally turned it into a full email. So I’ll just copy it below.
Hi all,Some interesting very recent developments over at MIT I thought worthwhile to share to this list:
We will soon have guaranteed transitional funding for all students across MIT who wish to leave an unhealthy advising relationship. They describe it here at this link. Announced Feb 19 / goes into effect Mar 8, and I think they didn’t start petition until maybe 6 months ago, so super fast in institutional terms (cough thanks Harvard for taking two YEARS to get us a one-year contract).
More about RISE:
Reject Injustice through Student Empowerment (RISE) is a united effort of MIT grad students led by Graduate Students for a Healthy MIT, Black Graduate Student Association, and Graduate Student Council Diversity, Equity, and Inclusion committee. Another to keep an eye on, FAARM, a policy-oriented approach which aims to use federal funding as a nation-wide lever to improve grad student mental health. Harvard Grad Council (which covers all grad students, not just SEAS) has actually already endorsed this.
FAARM objective: Mobilize the federal research funding agencies (FRFAs) and other leaders in U.S. R&D and higher education toimprove the advising and mentorship provided to graduate students.
You can sign up for their mailing list for progress updates, they also have a cool one-page summary over at their website.
Anyway, in other ways we’ve beaten MIT to the punch, we already have a grad student union. Our first contract (which Harvard appears to have signed in part when they realized COVID was going to be a big deal) was only a year-long contract and ends June 30, so we get to negotiate a new one again. https://www.thecrimson.com/article/2021/2/13/grad-student-union-second-contract/ I am unfortunately not technically a grad student right now (I’m just doing my research toward graduating unpaid, lol ), so you should join the union on my behalf! http://harvardgradunion.org/join/
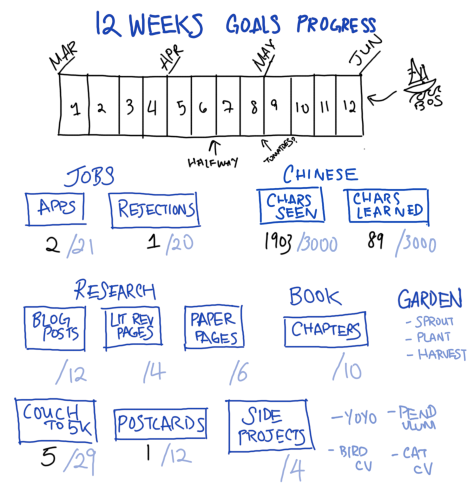
Next post will be a little graphic of my goals – what will it take for me to be happy with having been unemployed for a year?
Wait I guess technically I’ve only been unemployed for 3 months right now, so maybe more like… unemployed for half a year, living at home for 1.5 years. (oh god) (remember to be grateful)