Some disorganized thoughts (un-apologetically, I write this blog for myself)
being grateful is hard – it’s so easy to see inequities instead of being grateful for the opportunities i *do* have
it’s easy to look down on people and harder to reach out a hand – so what if people haven’t done the work or put in the time – as a community with a shared goal, just get people up to speed and running
academia really poisoned my mind into thinking everything is a competition,
or maybe it’s just my crappy path in academia made it feel like a fight to “survive” / persist in academia
i tend to project my self-doubt into the neutral actions of others – i should probably stop chewing off my lifelines lol
so, just have to believe in myself (perhaps). it’s hard to not depend on others when lost, but after startup-ing, I do hold confidence in
one of the things I’m bitter about is not feeling in a position to really mentor as much as I’d like
life is unfair! it’s a struggle for me to not let the anger over this impeded my progress in my career. so what if I joined grad school looking for stability and found so little? the key is to look forward to where to go from here
things i didn’t find in phd:
not having to think about gender / pay differentials
having stability of income and health insurance
i guess that’s it… but those are huge things, i mean to some extent like startups you could say i put myself in this position – i chose to pursue this phd, i am choosing to finish it even without being paid, i am choosing to not teach to get an income because i can’t juggle that and research… that i have the privilege to do so. i could just apply to a job
so, should i be mad or not? i guess we always have a right to our feelings u___u
i guess i have fewer ties so i have to spend less time worrying about family (have no grandparents, no cousins aunts uncles etc. in the US) falling sick to the virus.
being home, i’ve found it difficult to be frank on this blog; and now that i’ve been in a position of authority over others (have had students and mentees within the field) it’s even weirder…
just keep putting one foot forward in front of the other ! i need to stop feeling incompetent and just
get
work
done
todo: apply to internships, dissertation fellowships, complete workshop paper draft, finish contract work, make a puzzle, find… a research direction??? maybe i should start thinking of what i consider hackathon projects… and just complete those and publish them on this blog. i think that would motivate me more to finish things, than to find some abstract ideas. and it would at least force me to move things forward, instead of wait hopelessly for NDA access to come through.
Waiting for an NDA to make research progress… I believe there’s a great Chinese idiom for that
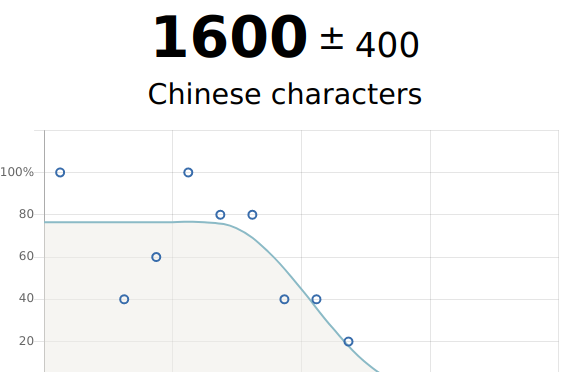
My side project of the weekend was adding examples to flashcards of the top 3000 characters in Chinese. After working through this deck I agree with the assessment that I probably only know about 1500 characters in Chinese. Documented on github: https://github.com/nouyang/ChineseScraper/ (privately for now but basically combine http://www.zein.se/patrick/3000char.html & https://ankiweb.net/shared/info/39888802)
So I’ve been working hard at improving my Chinese while I’m at home and my parents have the patience and skills to help me out on a daily basis. I remember going to visit my relatives in China and not being able to express more than that I was still in grad school and also cared about the economy (or something vague like that). It was really embarrassing, as it forced me to realize how much I relied on the English part of Chinglish with my parents, and made me really wish I could express myself better. (For context, I’m an ABC – American Born Chinese – and learned Chinese through Saturday school, which was organized by local Chinese parents at a nearby Church that had lent us some space. OMG and they had an ice cream vending machine so tasty).
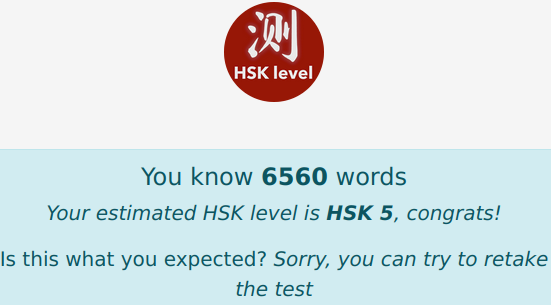
Anyway, depressingly, I probably only know about 1000-1500 characters :'( I guess the nice goal point would be 5,000 characters… I wonder how many I knew when I took my HSK test like a decade ago. Only one of them attempted to estimate words known (vs characters).
Current Status
Anyway for my reference (aka I will redo these estimators again in a year and hopefully see that I get more correct)
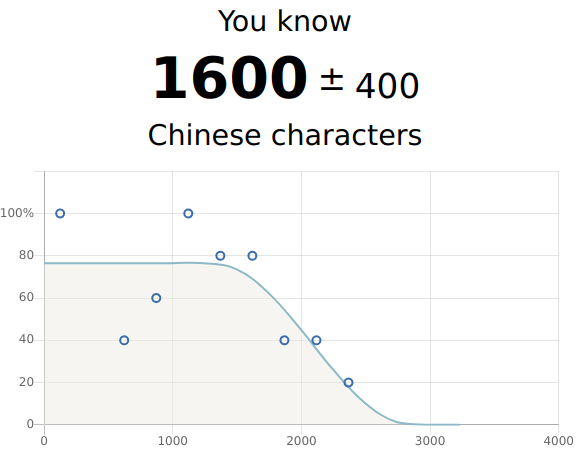
https://hanzitest.herokuapp.com/
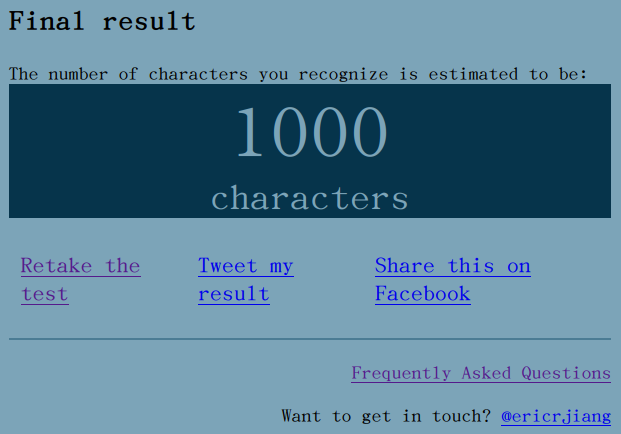
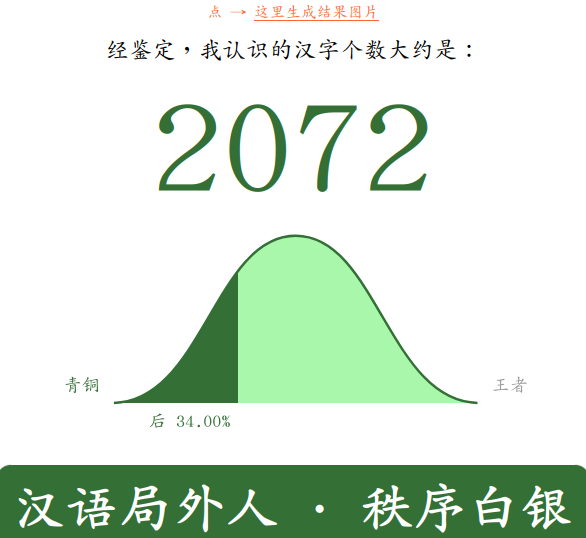
https://www.arealme.com/how-many-chinese-characters-do-i-know/cn/ — This one was impossible. Clearly aimed at native speakers (well, the UI being in Chinese was a strong sign lol).
The Chinese at the bottom says “汉语局外人 秩序白银” or Pinyin “Hànyǔ júwàirén zhìxù báiyín) = “Chinese Outsider, Order Silver”. Taking this test was definitely An Experience, highly recommend… they have devilish multiple choice questions like, given four (handwritten) characters, “which of these is NOT a real character” 0:
Speaking of Wordswing, besides this character test, it has a fun new way to learn Chinese: Interactive Fiction! Love the idea. Specifically, there’s WordSwing Chinese (Website). It’s just a normal interactive fiction interface, but with a built-in popover Chinese dictionary. Very cool!
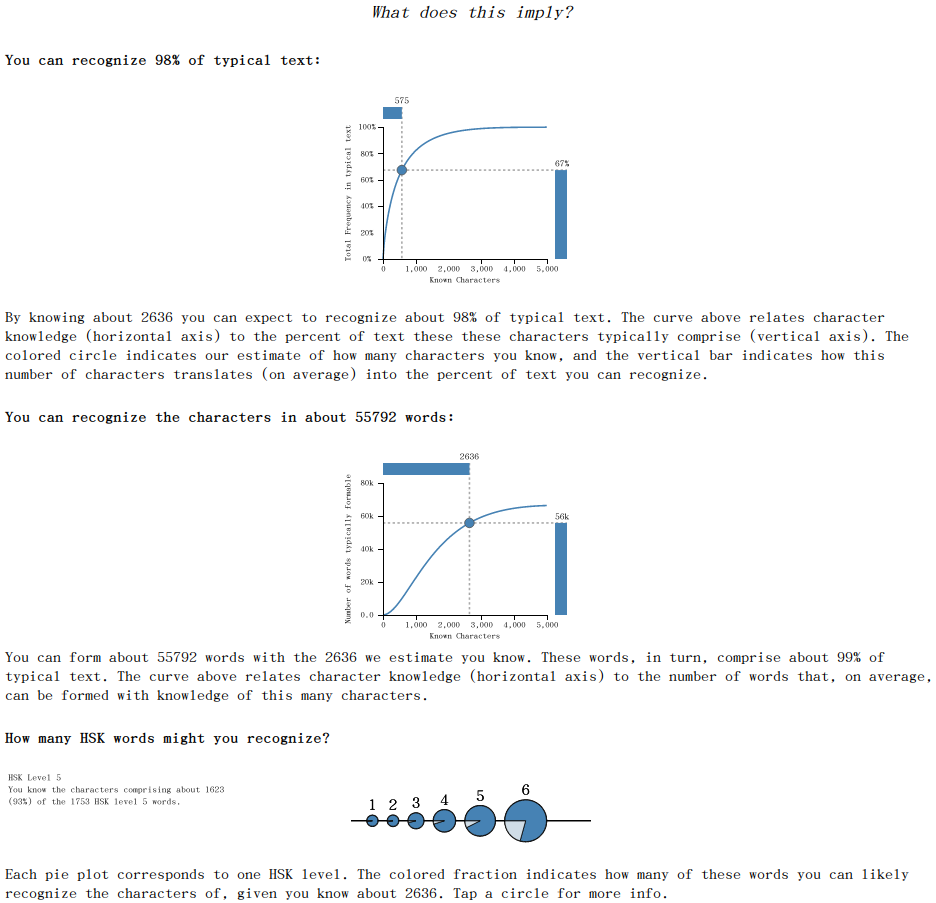
Back to WordSwing’s character test, if you click on “stats”:
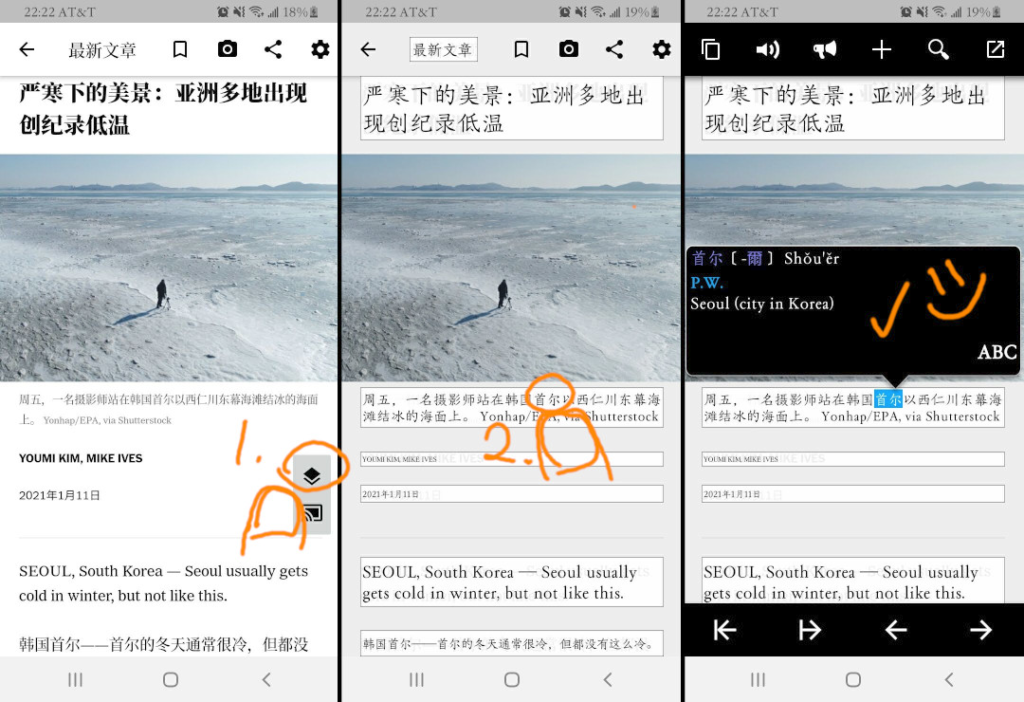
Pleco Screen Reader + NYTimes Chinese is a great combination!! (Note: I did pay for Pleco so I’m not sure if this “Screen Reader” tool is a default free feature)
1. NYTimes Chinese App (I selected Dual English/Chinese mode). Select “Screen Reader” Pleco tool 2. It pops up all the detected words, as “selectable” text 3. Press a word and get the Pleco dictionary result!
Anki
Anki has been eating like an hour a day to go over my cards (this is because I’m learning writing, so I have to physically write out the word!), + 3-4 hours once a week to pick out my mispelled words, add pinyin, and create cards… Finally today I got around to adjusting settings. This is unsustainable – I want closer to 20 mins a day (so 15 mins by the estimated time).
New Anki settings to take less time: New cards: 3 (instead of 20) Max reviews per day: 20 (instead of 200) Interval modifier: 150% (instead of 100%) Lapses > New Interval: 70% (instead of 0%) Tools > Preferences > Scheduling: New cards after Reviews (not sure default)
Compare to today, where i spent 45 minutes, studied 200 cards (out of 366 total cards). Of those 200, I reviewed 100 cards, and learned 60 cards (? I guess this is different than new cards, which was limited to 20), and relearned 39 cards.
So to 1/3 the time (45 -> 15 mins), I need closer to 30 review cards. I’ll be conservative for now and put it to 20 reviews. Save some time that I lost from all this over the next few days (probably use it all on making cards lol, but hopefully this will be more long-term manageable and I can spend more time on stuff I enjoy like reading).
Diary
Was supposed to be daily, but really lost it over the last week (due to elections / volunteering for the elections). I have not been putting them online because some of it might be kind of private / boring.
Pic for sense of scale. Sorry for the loading circle, screen-capped this from a video. Purposefully blurry so my embarrassingly misspelled diary isn’t there. That’s my dad’s hand as he helps fix my diary.
Reading a Novel
It has been my dream to read a full Chinese novel. Although this seems unlikely anytime soon, I did find a copy of MDZS which is the novel version of a TV drama I watched (and also read the wiki for). (Note: It’s immensely popular ‘cos the guys are cute, and there’s a lot of behind-the-scenes content to fan over, but to be honest the plot is questionable). Having watched the drama makes it SO much easier to follow what is going on, since I’ve had 50 hours to have the character names drilled into my heads (each of the 30 characters has 3 different names or something…).
Other useful bits:
Pleco has specific “Reader” settings: Turn on “Paginate Text” – otherwise it felt like floating in a sea of characters.
Also, you can set (Day) background color to be a lot less offensive light yellow color. And a better font was INCREDIBLY important!!
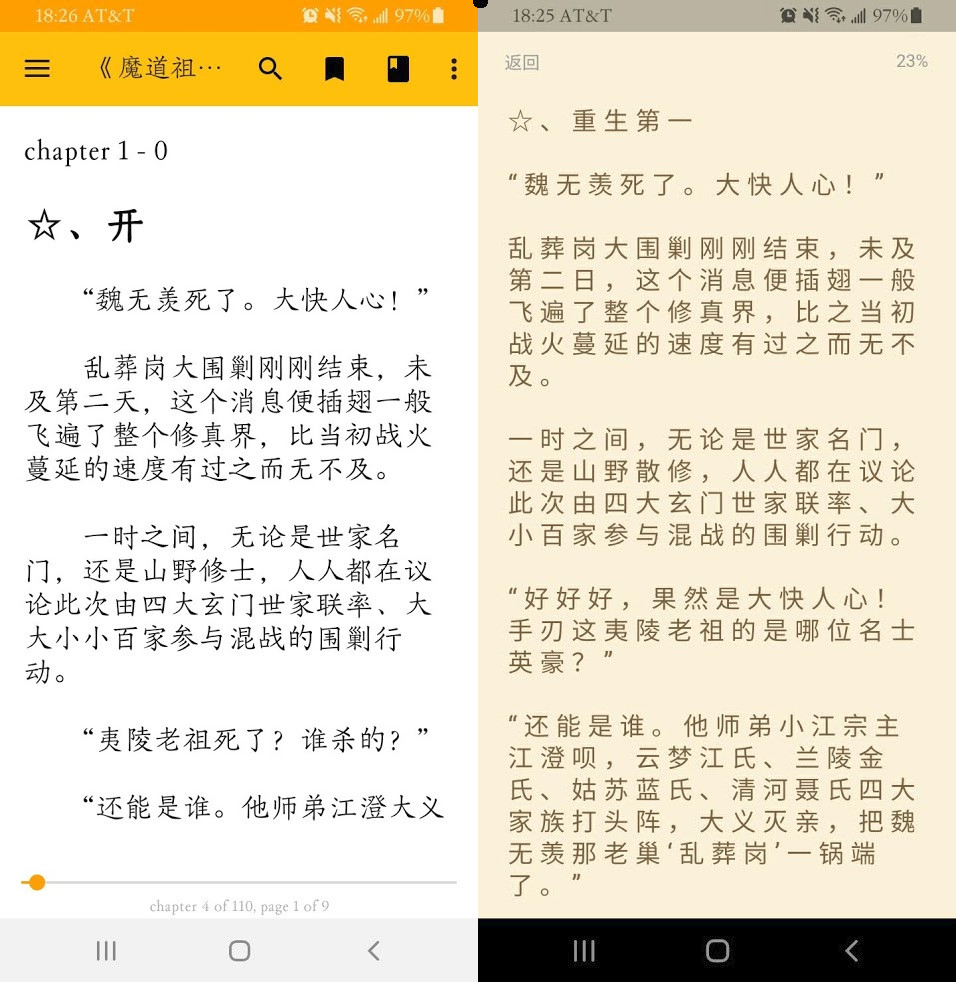
I spent $3 on a quality Chinese font for my Samsung phone(buying fonts is part of the built-in Samsung store) called “方正萤雪体“。 Somehow, it make reading large amount of texts SO much more bearable than the default squareish font.
Then I used it in Pleco reader (had to set Fonts > Built in Fonts) to get Pleco to use the new font.
Compare the $3 font vs the default font… The expensive font is so much more readable for me! Definitely worth it.
I also got it to work in Anki, though I won’t go through how I got it to work.
Immersion
I also switched fonts on Ubuntu to use the UKai font. And also installed SunPinYinIME which is soooo much better than whatever Ubuntu IME I was using before (sudo apt install ibus-sunpinyin, I think). It has a much better “autocomplete” which is critical for typing Chinese — before, the IME was so bad, that it was faster for me to type Chinese on my phone!!
I’ve started occasionally toggling my cellphone to be in full Chinese for the settings. I also set my Switch (which I got recently — story for another time) game to be in Chinese settings.
Switch: Ring Fit Adventure
Google Lens helps a lot with that. I can point my cellphone at the screen, take a picture, and copy the text out using google lens. Then put it into pleco. Much faster than writing it all out.
Podcast?
I’ve still not found a good Chinese podcast that hits my interest points. So far I just occasionally listen to a radio broadcast of news from some city in New Zealand, Waikato Chinese Voices.
Conclusion
I definitely have more patience for reading Chinese – I can get through a paragraph or two of a newspaper article by myself, and the whole article with Pleco helping. But it would to be able to quantify that, or have a goal to work towards. (like … learning 5000 characters, but I am apparently so far from that, that I don’t know that I will be motivated to just brute force learn characters). I just can’t help but feel some more targeted learning would help me progress faster. But for now, I’m just happy I’ve been able to be fairly consistent about actively learning Chinese for over a month now.
Whew this blog post turned out WAY longer and took way more time than I anticipated. Happy 2021 everyone!
Appendix Anki
Imagine that you notice you’re hitting Easy all the time. You’re seeing cards again too soon. Now you could just have patience and know that if you keep on hitting Easy, the intervals will grow, and eventually you’ll end up with appropriate intervals. But a better option is to increase the interval modifier from 100% to maybe 150%.
IIRC the anki defaults seem to be geared more for short term, dense studying (like for tests). In those situations you would want a lapse to reset the interval to 0. For longer term learning, you ideally want an 80-90% recall rate.
Imagine that you notice you’re hitting Easy all the time. You’re seeing cards again too soon. Now you could just have patience and know that if you keep on hitting Easy, the intervals will grow, and eventually you’ll end up with appropriate intervals. But a better option is to increase the interval modifier from 100% to maybe 150%.
Elections: Hot potato we fricking did it!!! Turned Georgia blue, swept BOTH seats! Canvassed 49 doors (for no good reason TBH but I figured better than sitting at home, got some exercise and got to see more parts of GA) on Tuesday. Not much mention of AAPI in the press but that’s okay. Watched results on wbstv / c-span.
Met someone who took leave like me – but for an analytics position lol. Ain’t no one asked me to deal with the pandemic, elections like this. Hardly making any progress on trafficking research. Honestly not too proud of myself right now.
Still think a lot more can be do in a decentralized manner, but hard to argue with results. (e.g. competition to have voter registration drives in every high school – though I think that’s moot since you’re registered by default when you get your driver’s license now in GA! Which is pretty darn cool.) (But another goal would be more like “adopt a neighborhood” rather than this turf-cutting. Just have people you talk to every year. Instead of once an election. Feel cut-off from other volunteers. Maybe exacerbated by pandemic. No watch party to see first wasserman, then AP, etc. call the election for Warnock and Ossoff!!)
Capitol riots insurrection: Frickin surreal to see. Heard rumors but dismissed them. Members of congress in plastic gas masks crouched under low balconies.
ask that all insurrectionists be arrested, at the very least have this on their record in some form. there should be thousands of arrests… cannot allow people to think they have this amount of entitlement and privilege!!
thank secretary of state of GA Raff. and Sterling
thank local election officials / staff
congrats to bordeaux, ossoff, warnock!!
Do research?! Write cat book? T__T I really need to get off news sites.
So glad not to have to listen to Trump’s ranting on Twitter while elector confirmation finished. Watching on https://www.pbs.org/newshour/ . Real world consequences of disinformation…
Too much reddit, 538, twitter. Got to get my own work done. Finish projects so I feel productive again. 2021 off to a shaky start in productivity.
Was hoping lack of instant arrests vs BLM protests was 1. Trump denying the use of National Guard 2. Pentagon or whomever learning from BLM protests what it means to de-escalate.
But lack of arrests… lack of people on no-fly lists… And then;
“Protesters in Kansas entered the state Capitol building, said Tom Day, the director of legislative administrative services, but they were allowed to stay and remained peaceful as of the late afternoon.”
What in the everloving f*ksticks? I’m ashamed. Real ashamed. Ain’t no pretending it’s “bad apples” now hopefully. The contrast is just too severe. I am glad to come to my senses on BLM this year.
(Hope to do some primary research on China, HK and Uighur this weekend. Form some opinions finally, not just feelings)
What draws people to power and to try to keep power like this? Why did they decide to become politicians? It’s certainly not a pleasant job. Bunch of 80 year olds up until 4AM holed up with Covid. (maybe they got vaccines already)
In the meantime, COVID, COVID. Me: Nearly 4,000 Americans died yesterday Parents: What? No, the world would be in uproar over that, we would’ve heard! No it was four people. Me: … of COVID *crickets*