
The past week with one of my graduate classes, we read a few papers on probabilistic programming lanugages (PPLs). A few fellow students presented on the papers, and included a little hands-on demo of PPLs. They’re much more approachable than I thought!
At least in the “hello world” cases, they’re pretty much like normal
programming languages with the addition of a few primitives to allow for
reasoning about probabilities. In the example of CHURCH, this is the flip primitive. CHURCH uses LISP-like syntax. [1]
Without further ado here are some of the examples given.
CHURCH
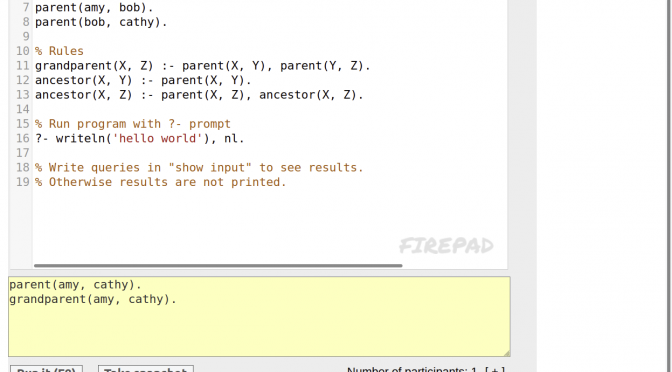
Here we use the online compiler at http://v1.probmods.org/play-space.html.
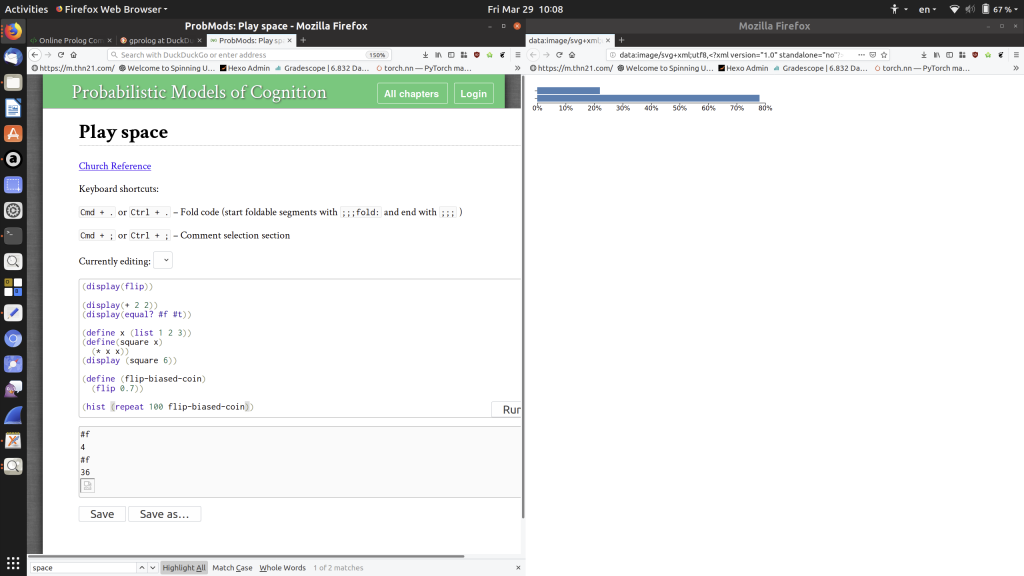
[2]
The first line, display(flip), shows one coin flip (50/50) – in this case we get a` #f, or false. If we run the program again, we might get a #t. Near the end, we see that we can also call flip 0.7 which will return true with 70% likelihood. We then run this 100 times and draw a histogram (I had to right-click and view the image in a new window to see it). Here we can see that we actually got about 78%-22% on this run. If we run the program again, we get a different histogram, and with more flips we get closer to the true 70% distribution.
Prolog
To see an example of how we can use PPLs to perform inference, let’s see an example in prolog.
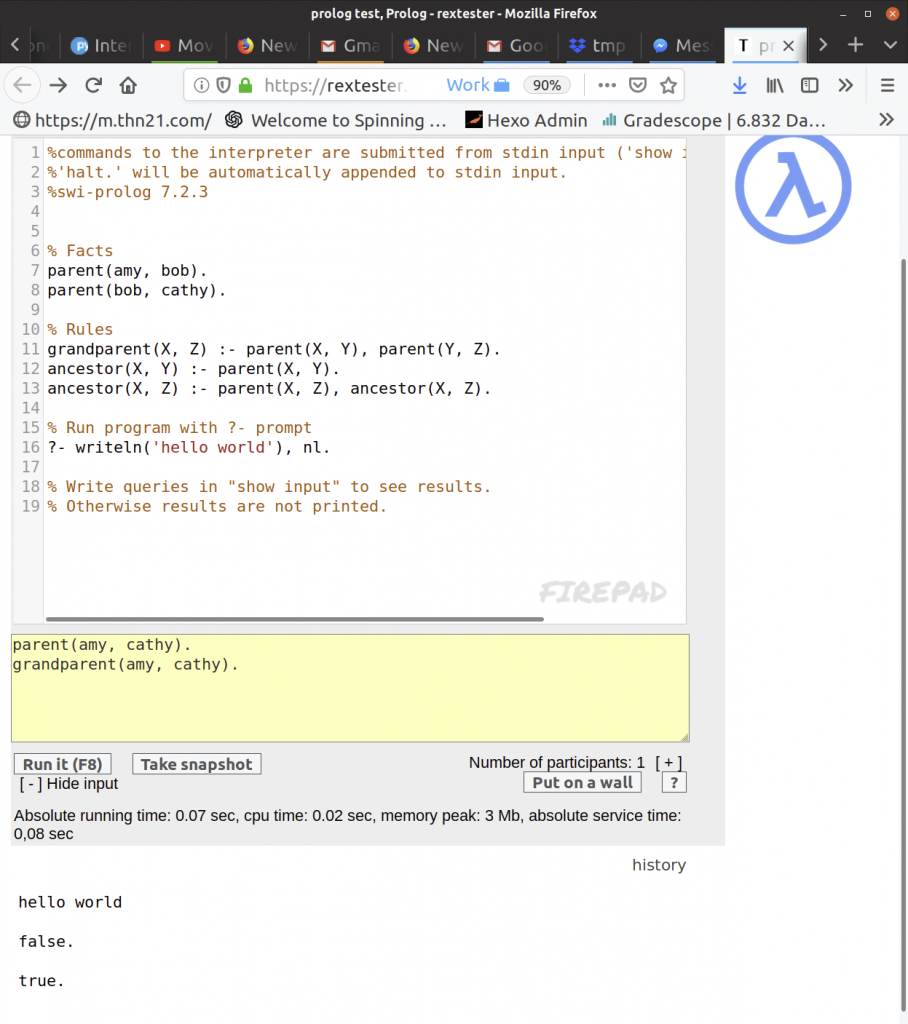
Follow along here.
https://rextester.com/l/prolog_online_compiler
Here we defined some facts (amy is a parent of bob, and bob is a parent of cathy). Then we defined some rules (what does it mean to be a grandparent?). Finally, at the bottom, I typed in some queries to find out of cathy is a parent of amy (no) and if amy is a grandparent of cathy (yes). Then I clicked Run it and got the output at the bottom.
In this way we see prolog has “reasoned” and created a causal chain from our question to the axioms we have.
We can also write our queries directly into the program, and print them all out.
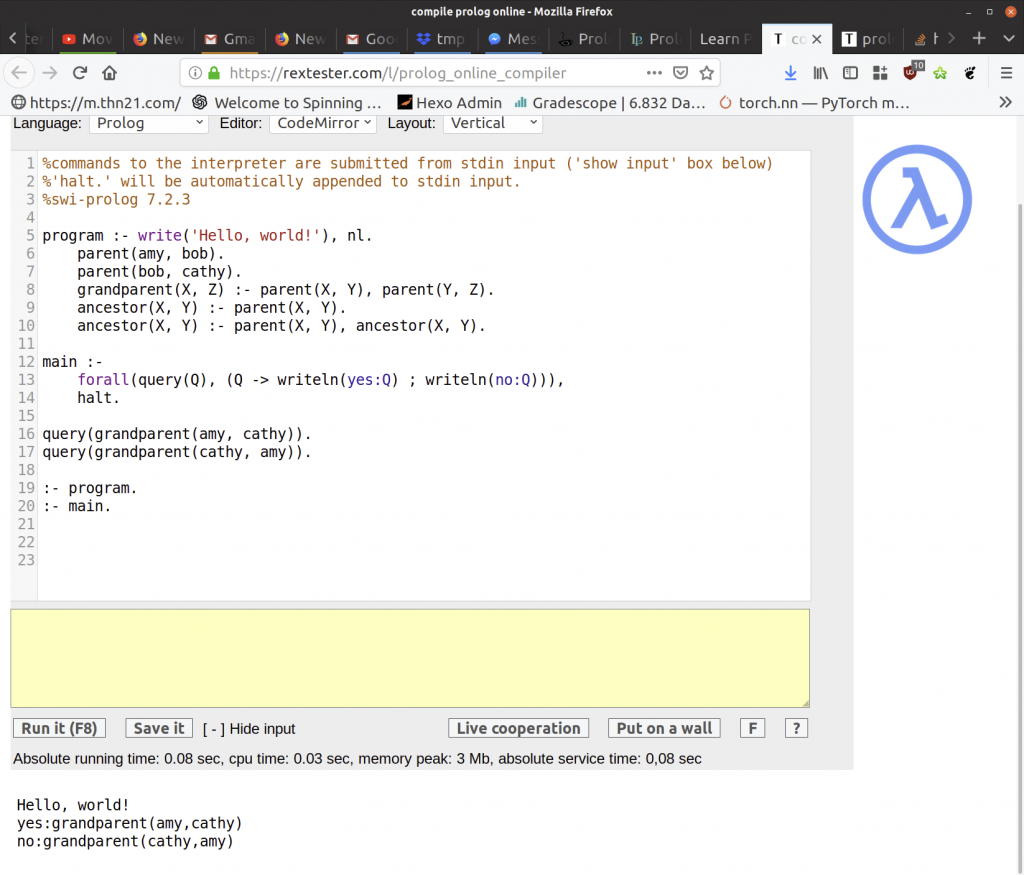
The code for these examples can be found at these links or the bottom of this post.
I’m not sure why prolog doesn’t have this concept of printing query
results. I had a lot of issues with the program not stopping (TIMEOUT)
and not being sure where I should type in the queries (marked with ?- in online tutorials), versus typing in the program itself.
Other thoughts
I also learned that they’re not just toy languages for computer science people, and there are statistical researcher who use these on a daily basis.
Footnotes
[1] The instructor said something like “Yea I feel like all these probabilistic programming languages and always in some obscure language. For instance CHURCH targets the niche that knows both LISP and the relevant statistical concepts. They’re mostly useful for the authors.”
[2] Note: Like LISP, the strange operator order is Polish notation.
Appendix
CHURCH
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | (display(flip)) (display(+ 2 2)) (display(equal? #f #t)) (define x (list 1 2 3)) (define (square x) (* x x) (display (square 6)) (define (flip-biased-coin) (flip 0.7)) (hist (repeat 100 flip-biased-coin)) |
Prolog 1
This should be input in their entirety into the coding area, and then run.
| 1 2 3 4 5 6 7 8 9 10 11 | % Facts parent(amy, bob). parent(bob, cathy). % Rules grandparent(X, Z) :- parent(X, Y), parent(Y, Z). ancestor(X, Y) :- parent(X, Y). ancestor(X, Z) :- parent(X, Z), ancestor(X, Z). % Run program with ?- prompt ?- writeln(‘hello world’), nl. |
Prolog 2
This should be input in their entirety into the coding area, and then run.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | program :- write(‘Hello, world!’), nl. parent(amy, bob). parent(bob, cathy). grandparent(X, Z) :- parent(X, Y), parent(Y, Z). ancestor(X, Y) :- parent(X, Y). ancestor(X, Y) :- parent(X, Z), ancestor(Z, Y). printqueries :- forall(query(Q), (Q -> writeln(yes:Q) ; writeln(no:Q))). query(parent(amy, cathy)). query(parent(bob, cathy)). query(grandparent(amy, cathy)). query(ancestor(amy, cathy)). :- program. :- printqueries. |