i got excited about robots again, which is a happy thing for me.* i watched some young ‘un training up an arm to put legos in a bowl in the space of a few hours and was curious, and holy smokes, manipulation has just bounded ahead in the last 2-3 years.
* apparently it’s been about 10 years, obligatory wow i’m old, the staubli arm post is here: https://orangenarwhals.com/2017/07/staubli-arm/
i decided to invest in my future and get a pair of robot arms (it’s great to not be a self-employed grad student anymore), it’s ca. $300 for two robot arms (T__T so expensive) — one a leader, one a follower. the name of the game (for at least a year or so) has been teleoperation data (?? i guess they just decided to throw money and scale this) which seems dumb but has been remarkably effective (see: bitter lesson).
3d print
i even took the STLs and sliced them with tree supports myself *gasp* instead of printing a model from makerworld eheh. See: https://github.com/TheRobotStudio/SO-ARM100#printing-the-parts
assembly thoughts
well i’m a bit lazy to document everything, but here are some thoughts:
CHINAMIXELS — as a friend put it — chinese dynamixels ! get position feedback out. they’re expensive still ($20 each) but at least i no longer make $20k a year so eh?
the main issue with the assembly was the holes were too small for the screwdriver to fit through, so i was drilling out the hole with the screwdriver … also i realized a bit late that there were official docs for the seeedstudio version, not just generic ones,
https://wiki.seeedstudio.com/lerobot_so100m_new/
and also there was a 12.4 v power supply and a 5 v power supply.
also assigning ids to motors is ideally done before assembly because it’s a pain after assembly to detach and attach the servo wires.
also getting the horns onto the servo does involve some force, and some trickery to getting them off again (wiggle side to side with a screwdriver).
also why didn’t they just put numbers and labels on the 3d printed parts ?? it takes some figuring out which pieces go where. SIGH. i would’ve added those features *shakes head*

alright. anyway after some fuss i assembled the arms. not sure i got the handle right (the purple is the “leader arm” but eh.
so after some fuss with the motor id stuff, followed by the calibration (the follower does seem smart enough to not go past the bounds you calibrate it to, but still map correctly to the leader arm)
teleoperation
i finally got teleop working 😀
keep truckin’ through the readme, set up cameras
alright so i have a wrist-mount camera which is like a raspberry pi camera, but it has a board-to-USB cable instead of going through a ribbon 0: then I can print out the camera adapter
(shown here mounted with tape, but actually it just takes 2x M3 screws and then the camera module is screwed in using four of the leftover feetech servo screws)

https://wiki.seeedstudio.com/lerobot_so100m_new/#if-using-a-regular-camera
& collect data: input = teleop motor joints + camera feeds
then after that got the weird training code semi-working (really need to figure out the keyboard controls, killed my whole python environment trying to get it working).
i recorded and got episode replay to play it back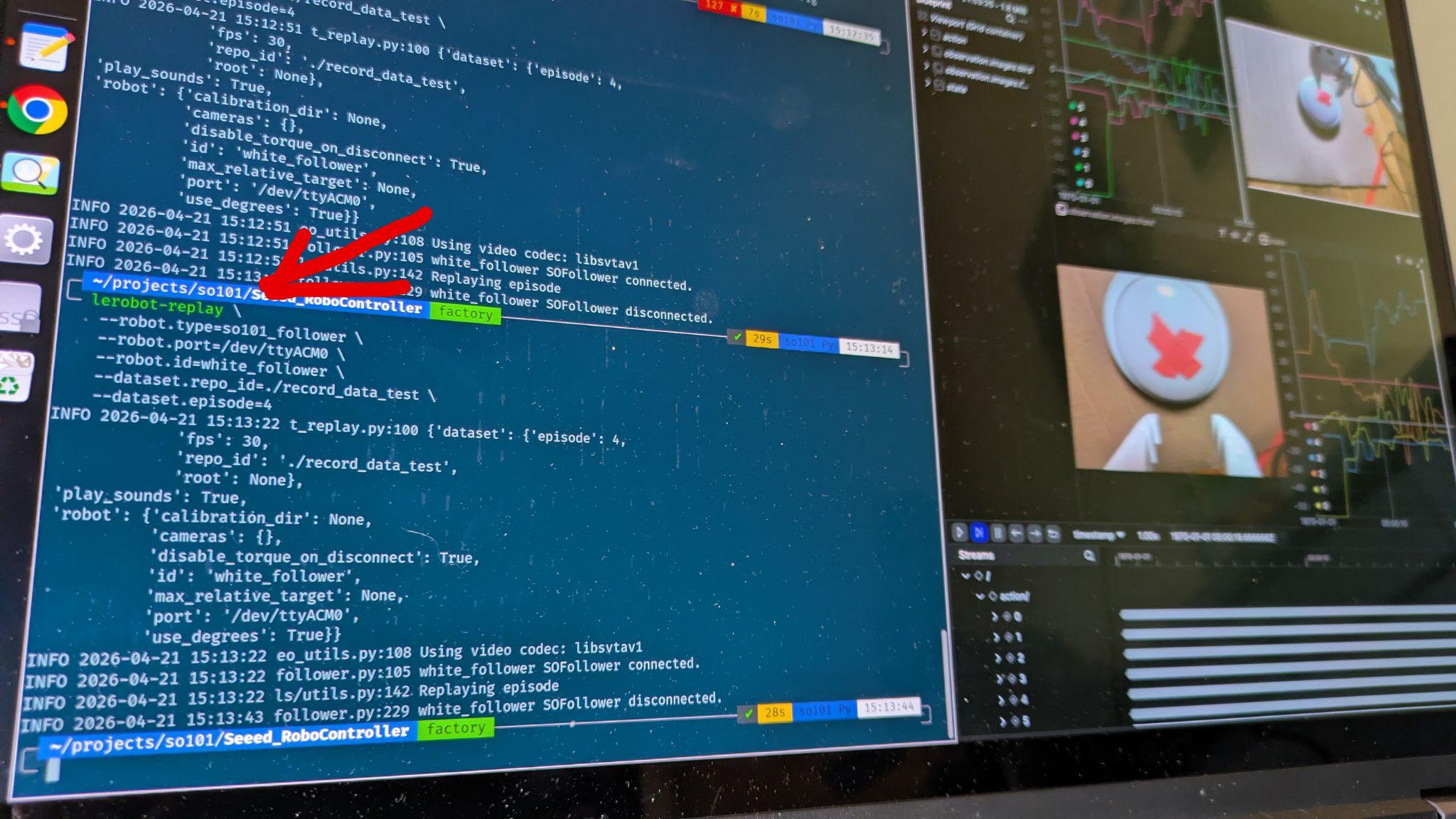
[ Note: i have some built-in fear from my first experience with commercial robot arms, which was an industrial staubli machine that moved FAST. it was not a collaborative arm and it would commit violence on its way to a home position without a second thought. ]
there’s tape on the bottom of the button to keep it from sliding around. i put a taped-cross on it in the theory that it would make learning faster, but decided the task was too annoying to try to collect an hour of data for.
what’s next?
in the above data collection, wanted to give it the task of “turn on the light” — but actually that button is real annoying to press with the robot arm / manipulator.
i feel apologetic to my cat for making it push buttons.
so, what’s next? actually collecting data and training.
and after that … i’m getting a ur5 tomorrow huehuehue
Fin.
[ personal note: life has been topsy turvy* so i’ve been pretty quiet. but i also told myself that once i graduated (my phd) i’d be free to be really honest about things. i’ve been following general advice (how to be professional) but starting to feel like i get better results being myself, because well, i’m myself. (this includes my derpy enthusiastic side, but also includes my self-studying physics c self that was fearless about whiteboarding math up)
*i’m unemployed again *laugh cry* now i have stories aplenty. from 16x A100 GPUs idling doing nothing, to *other stuff* . at least i did manage to kill some of my imposter syndrome through just how bizarre my jobs have been. time to look for an in-person job, which should be easy with robots ]