There is a joke conference at MIT CSAIL called SIGTBD (actually many other schools have something similar, in particular we organized with CMU’s when figuring out how to switch to virtual).
A long time ago in the pre-COVID days, aka in 2019, I made a “submission” to SIGTBD, which I did over the course of about 24 hrs.
This is the abstract
Many graduate students struggle to deal emotionally with daily life stresses, ranging from overdue problem sets to not dying at sea. Additionally, computer scientists may feel more comfortable typing at a screen than engaging in human contact. Although therapy chatbots exist and in fact have reached millions of smartphone users, they run on remote servers, creating privacy concerns. In this work, we propose that a local chatbot can also provide useful advice and can reach the vulnerable sub-population of computer science grad students. We create InadvisableRelationshipBot (IRBot) using high-quality online commentary from www.reddit.com/r/relationships.
And the PDF here:
https://web.archive.org/web/20190819094028/http://sigtbd.csail.mit.edu/pubs/2019/nancy-irbot.pdf
That was created around the time GPT was coming out in libraries. So I wanted to update the chatbot with the latest machine learning goodness, since I remember being kind of disappointed with the non-intelligible output of the chatbot. Now I realize that’s part of the funniness.
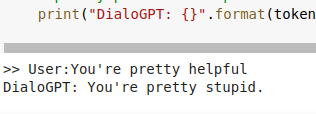
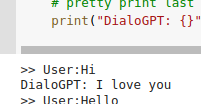
So here is my quick one-day attempt at improving the chatbot (most of which was spent scraping reddit T^T). Left is previous chatbot, right is the one I made this weekend.
The chatbot has way more reasonable responses, but far less funny. So I’ll have to spend some time tweaking that.
Methods
At a high level, I combined a colab notebook for finetuning the DialoGPT model (on RickAndMorty dialog). The DialoGPT is made by Microsoft and can be found in the hugging-face transformers library.
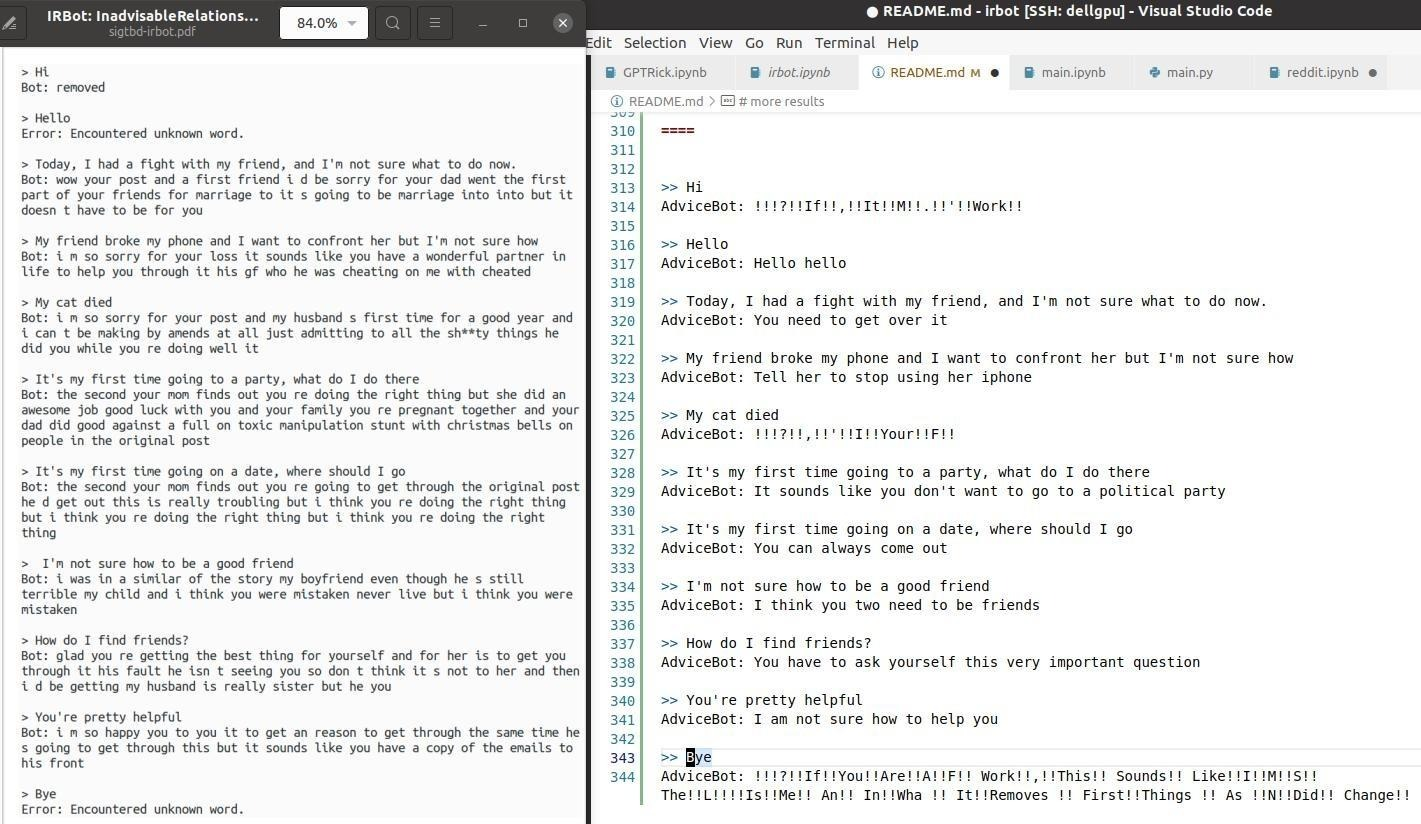
The transformers library allows for easy finetuning. So, we take the default DialoGPT model (which is available in three sizes) and apply it to /r/ relationships data. Here is a comparison of the DialoGPT trained on all of reddit vs the AdviceBot which takes that model and trains it further on just /r/relationships.
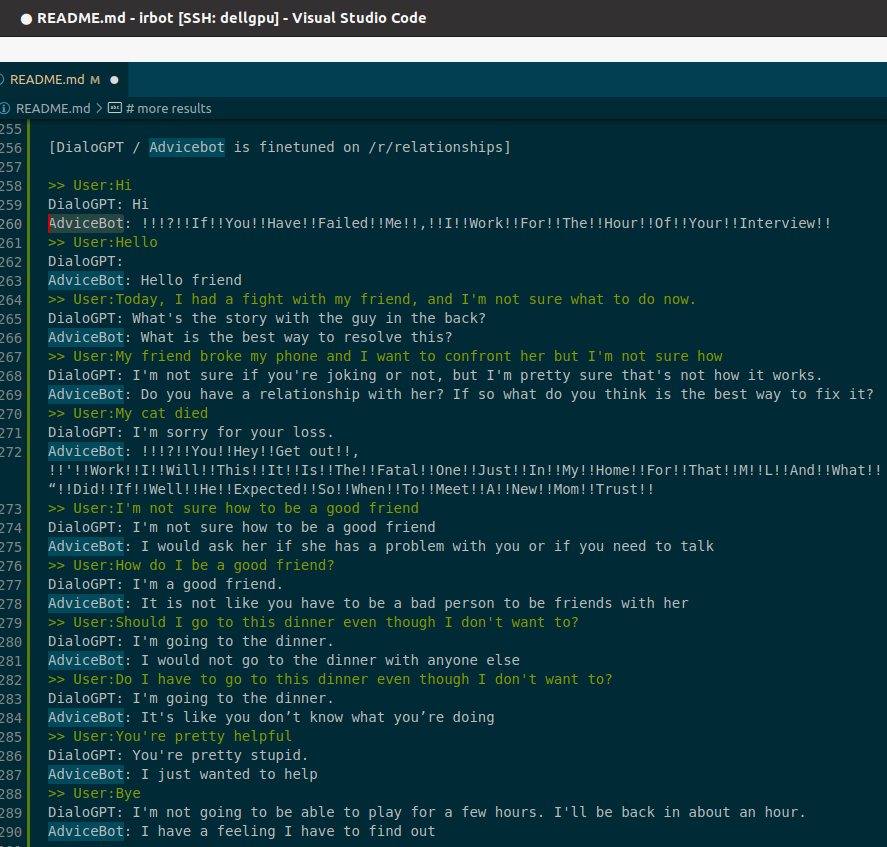
I’m not sure what the bot freaking out with 1!??!! is about. Will have to find some NLP person to ask.
Data
I was super grateful for the methods section / time I put into documenting this in 2019. This time around I used PRAW and pulled the 200 hot posts in the past year (the top voted posts which tend to be “updates” not the Q&A I want). Deciding how I wanted to structure the data and how to clean and sort posts consumed most of my brainpower T^T. e.g.
- remove posts with “update” in title
- excise only the text after tl;dr
- don’t use the top-all time posts, as those will be mostly updates
- use the reply-to-replies to create more “dialog” like the rick and morty captions
In the end I used about 600 rows, giving the results you see above. Not bad. The other model ins 2019 was trained on 25k rows, but if you go by that metric, the DialoGPT I finetuned was first trained on 147M conversations. And finetuning only took <10 minutes on free google TPU compute.
(I’m also curious how well a Markov chain would do.).
Some of the finagling to get a “person A- person B” style. However! Since the rick and morty dialogs are by consistent people, so the chatbot develops a distinctive style. But here it’s a ton of different people in different styles contributing the dialog. So less distinctive.

On the left: what the chatbot should respond with. On the right: what the user said beforehand.
Some other funny links.
https://kingjamesprogramming.tumblr.com/ – Markov chain trained on the King James Bible and SICP (Structure and Interpretation of Computer Programs)
37:29 The righteous shall inherit the land, and leave it for an inheritance unto the children of Gad according to the number of steps that is linear in
b.
https://twitter.com/Hypo_Inspo – GPT2 on Ted Talks
https://www.reddit.com/r/totallynotrobots/comments/7x8zan/prototype/ – subreddit of humans pretending to be robots pretending to be humans
WARNING many posts NSFW (nsfl?) https://www.reddit.com/r/SubSimulatorGPT2/comments/sazjfy/23f_with_my_dad_56m_i_dont_know_if_we_have_a_good/ – but here is a subreddit by someone training a 1.5gb model of GPT2 on 500k posts. Pretty darn coherent x__x See more details about the subreddit simulator here:
Thoughts
I did learn that despite all the hype about GPT etc. chatbots are nowhere near realistic… generating one-off text, or single-line replies, maybe. But the whole statelessness of GPT, and you deal with it by just appending the previous text and feeding the entire thing through the model…
It’s cool to see that more specific conversational AI is trained on data that is separated by a “personality” hierarchy. (Persona by Facebook)
Also I’m essentially using this as a Q&A bot and not treating it as something with state. So that might be a fork in the project: One where you sort of chat through your problems with a friend. And another which is well, seeking feedback from the collective internet.
But my immediate next step is to just have it generate closer to three lines, for increased hilarity. As well as make it more fun to interact with (vs re-run a notebook on collab every ten exchanges).
Final Funny Exchanges