
just documentation for myself while still fresh in my head.
Here’s the simplest version. More details to follow (coloring terminal output, adding timestamps to a log file, explaining some of the delay and log settings, etc.)
Overview
- Create a
CrawlSpiderclass - Inside have a
start_requests()class, where you take a list of urls (or a url) and yield ascrapy.Request()that calls a function you define (e.g.self.parse_page())- Note use of a
base_url, this is because often links on a page are relative links
- Note use of a
- Create the parsing function called earlier, e.g. most commonly use
response.css()(and same as normal css selectors – period to select a class, :: to select the plaintext that’s inside a set of tags, or::attr()to select a specific attribute inside the tag itself - Create a dictionary of the desired values from the page, and yield it
- Create a CrawlerProcess that outputs to CSS
c = CrawlerProcess(settings={
"FEEDS":{ "output_posts_crawler.csv" : {"format" : "csv"}}
})
- Call the CrawlerProcess on the CrawlSpider defined earlier, then start the spider
c.crawl(PostSpider)
c.start()
Here is some
example code
$ vi my_spider.py
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.crawler import CrawlerProcess
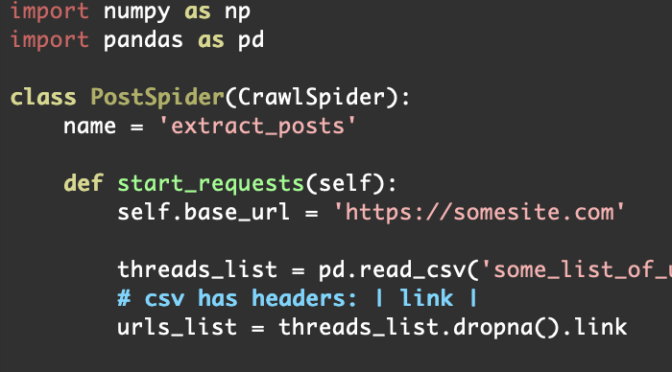
import numpy as np
import pandas as pd
class PostSpider(CrawlSpider):
name = 'extract_posts'
def start_requests(self):
self.base_url = 'https://somesite.com'
threads_list = pd.read_csv('some_list_of_urls.csv')
# csv has headers: | link |
urls_list = threads_list.dropna().link
for url in urls_list:
url = self.base_url + url
self.logger.error(f'now working with url {url}')
yield scrapy.Request(url=url, callback=self.parse_page)
def parse_page(self, response):
self.logger.info(f'Parsing url {response.url}')
page_name_and_pagination = response.css('title::text').get()
# - get post metadata
posts = response.css('article.post')
# <article class='post' data-content='id-123'>
# <header class='msg-author'> <div class='msg-author'>
# <a class='blah' href='index.php?threads/somethreadtitle/post-123'>
# No. 2</a>
# </div> </header> </article>
for post in posts:
post_id = post.css('::attr(data-content)').get()
post_ordinal = post.css('.msg-author a::text').get()
self.logger.info(
f'Now scraped: {page_name_and_pagination}')
page_data = {
'post_id': post_id,
'post_ordinal': post_ordinal}
yield page_data
c = CrawlerProcess(
settings={
"FEEDS":{
"_tmp_posts.csv" : {"format" : "csv",
"overwrite":True,
"encoding": "utf8",
}},
"CONCURRENT_REQUESTS":1, # default 16
"CONCURRENT_REQUESTS_PER_DOMAIN":1, # default 8
"CONCURRENT_ITEMS":1, # default 100
"DOWNLOAD_DELAY": 1, # default 0
"DEPTH_LIMIT":0, # how many pages down to go in pagination
"JOBDIR":'crawls/post_crawler',
"DUPEFILTER_DEBUG":True, # don't rescrape a page
}
)
c.crawl(PostSpider)
c.start()
$ python my_spider.pyend
that’s all folks